Two years of squash merge
 Simone Carletti
on
Simone Carletti
on
At DNSimple we use pull-requests every day as a standard workflow to propose, review, and submit changes to almost any git repository. For most core repositories, such as the DNSimple web application, or our Chef-based infrastructure, our policy is to not commit to master, but make changes into a separate branch, open a pull request, obtain a review from one or two people (depending on the change), and then merge the branch into master before deploying.
A little more than two years ago, we decided to change the development team's workflow to always use git --squash merge. In this post I will highlight the reasons for this decision, how it worked for us, and what the benefits are.
git merge: fast-forward, recursive, and squash
Before we get into the details of why we adopted the --squash merge, let's have a quick look at the most common merge strategies in git.
Note
This is definitely not a comprehensive explanation of the git merge command. For more in-depth explanations, take a look at the documentation for git merge.
First of all, the purpose of git merge is to incorporate the changes from another branch into the current one. For simplicity, we'll assume we want to merge a branch containing our changes called bugfix into the branch master.
fast-forward
If master has not diverged from the branch, when it's time to merge git will simply move the reference of master forward to the last commit of the bugfix branch.
C - D - E bugfix
/
A - B master
After git merge:
A - B - C - D - E master/bugfix
Here's the output of the merge:
➜ merge-examples git:(master) git merge --ff bugfix
Updating 9db2ac7..3452cab
Fast-forward
This is known as fast forward.
No fast-forward
The default behavior of Git is to use fast-forwarding whenever possible. However, it's possible to change this behavior in the git configuration or passing the --no-ff (no fast-forward) option to git merge. As a result, even if git detects that master did not diverge, it will create a merge commit.
C - D - E bugfix
/
A - B master
After git merge --no-ff:
C - D - E bugfix
/ \
A - B ------------ F master
Here's the output of the merge:
➜ merge-examples git:(master) git merge --no-ff bugfix
Already up to date!
Merge made by the 'recursive' strategy.
Recursive strategy
So far, we assumed that master never diverged from the bugfix branch. However, this is quite unlikely, even in a small size team with multiple developers working on several different changes at the same time. Take the following example:
C - D - E bugfix
/
A - B - F - G master
The commits F and G caused master to diverge from bugfix. Therefore, git can't simply fast-forward the reference to E or it will lose those 2 commits.
In this case, git will (generally) adopt a recursive merge strategy. The result is a merge commit that joins the two histories together:
C - D - E bugfix
/ \
A - B - F - G ----- H master
Here's the output of the merge:
➜ merge-examples git:(master) git merge --no-ff bugfix
Already up to date!
Merge made by the 'recursive' strategy.
Squash merge
Squash merge is a different merge approach. The commits of the merged branch are squashed into one and applied to the target branch. Here's an example:
C - D - E bugfix
/
A - B - F - G master
After git merge --squash && git commit:
C - D - E bugfix
/
A - B - F - G - CDE master
where CDE is a single commit combining all the changes of C + D + E. Squashing retains the changes but discards all the individual commits of the bugfix branch.
Note that git merge --squash prepares the merge but does not actually make a commit. You will need to execute git commit to create the merge commit. git has already prepared the commit message to contain the messages of all the squashed commits.
What problem are we trying to solve?
The main reason we decided to give --squash merge a try was to improve repository commit history quality.
Commits are essentially immutable. Technically there are ways to rewrite the history, but there are several reasons you generally don't want to do it. For the sake of simplicity, let's say the farther the commit is in the repository history, the more complicated it is to rewrite it.
It's important to write good commits because they are the pillar of your git history. It's hard to perfectly define what makes a commit a good commit, but in my experience, a good commit satisfies at least the following requirements:
- Combines all the code changes related to a single logical change (it could be a feature, a bugfix, or an individual change part of a bigger change)
- Provides an explanatory commit message that helps people understand the intent of the change
- If you pick this commit independently from the history, it makes sense on its own
Requirement one should be your default coding habit. A commit should represent an atomic change, and you should avoid combining multiple changes that are not related each other. Although this seems obvious, I've seen commits that change the compilation script as well as introduce a new feature in the app. Let's use another more practical example: you are fixing a bug, so we want the changes to the software to be committed along with the regression tests, not in different commits that are not related to each other.
Requirement two is a very well-known problem. There are hundreds of articles trying to define a good commit messsage and trying to teach the programmer the art of writing a good commit message. The official git contributing page has some guidelines:
Short (50 chars or less) summary of changes
More detailed explanatory text, if necessary. Wrap it to
about 72 characters or so. In some contexts, the first
line is treated as the subject of an email and the rest of
the text as the body. The blank line separating the
summary from the body is critical (unless you omit the body
entirely); tools like rebase can get confused if you run
the two together.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet,
preceded by a single space, with blank lines in
between, but conventions vary here
These guidelines are extracted from an article written by Tim Pope back in 2008. It's probably the oldest article I can remember on this matter.
So we've seen that writing good commit messages seems to be a hard rule to follow. We've also seen that there are some objective metrics you can follow, and some tools enforce or encourage these metrics:
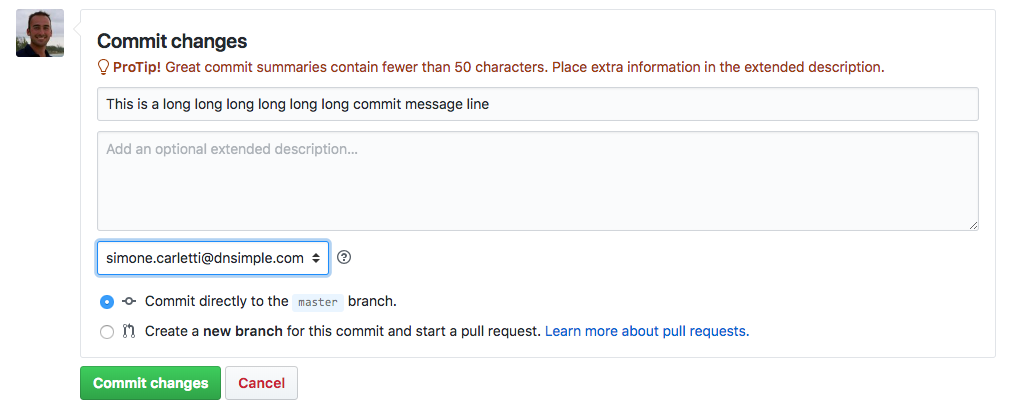
However, writing a good commit message is hard because it's not just a matter of following objective metrics. You can write a perfectly formatted but completely useless commit message:
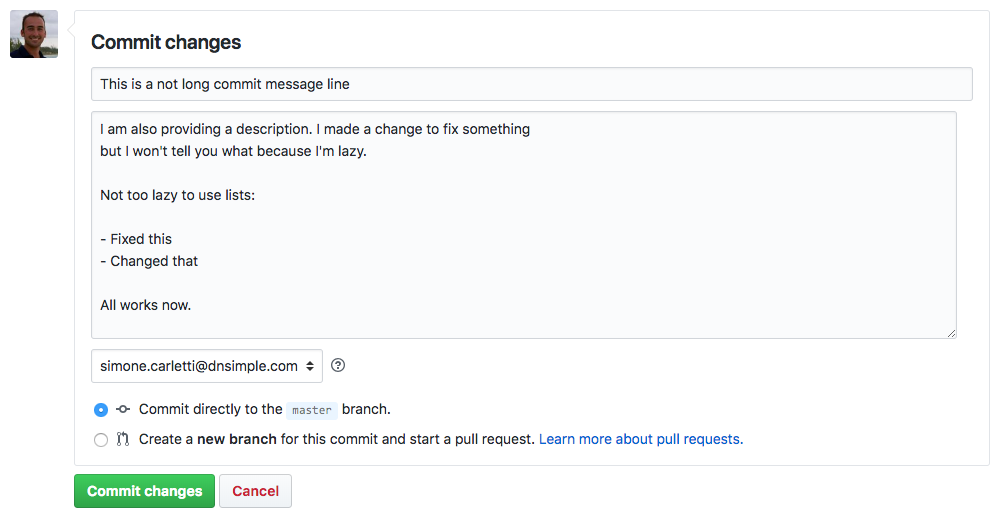
OK, an even more useless one:
Raise your hand if you ever created a commit with a message Fix test, Fix CI, Change foo, Add bar.
What is wrong with this commit message, you may be asking. This brings us to requirement three. A good commit (and a good commit message) is one that if you select that commit at any point in time from the hundreds of commits in the repository, it will make sense on its own (or will provide enough information to reconstruct the reason of the change).
Let's do an experiment. Can you tell me what this change is about?
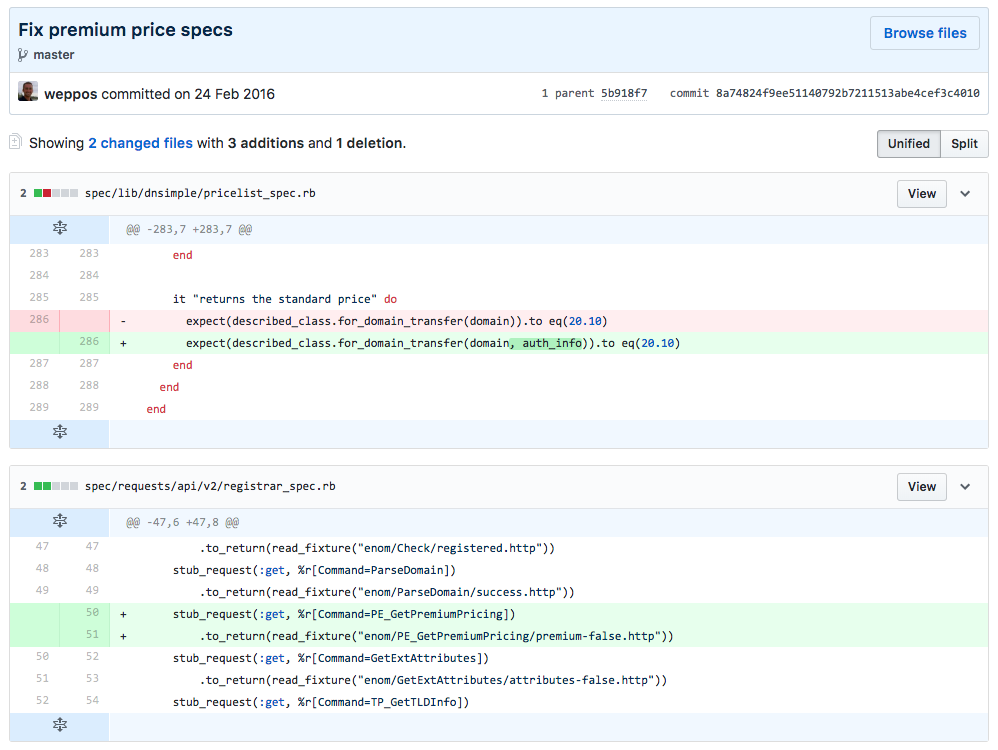
Indeed it fixes some specs with the goal to make them pass. But imagine if someone stumbles upon the changes on line 286 at some point 3 years from now. Neither the commit message nor the code explain why the specs were broken, when they were broken, what broke them, and why the change at line 286 was required. In isolation, this commit is quite meaningless.
Another common example of not very helpful messages is the first one in this history:
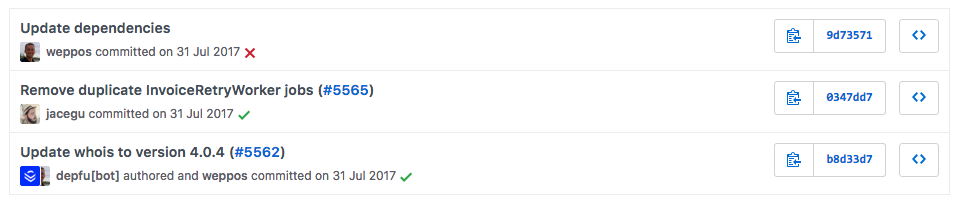
Imagine you are navigating through the list of hundreds of commits trying to investigate when and why something broke. I think you would agree that the effort required to determine whether the first commit could be a candidate to examine is higher than the third commit. From the message point of view, it requires you to (at least) open the commit to examine the changes.
Furthermore, the first commit may also break requirement one, because it includes several changes in the same commit. You may argue that updating multiple dependencies is a single logical change, but if that's the case, you are probably underestimating the impact of changing even a single dependency in a large project.
Advantages of git squash merge
Now that we know the problem, let's see how squash merge can help us.
As I explained before, using squash merge will bundle up all the changes in a single commit, also giving us the chance to write a fresh, complete commit message that properly describes the intent of the changes.
Using commit messages is a great way to limit the presence of isolated changesets in your codebase. It drastically improves the quality of the code that is living on the primary repository branch, ensuring only independent, self-contained changesets are present.
Here's an example of what the history of the DNSimple app looks like:
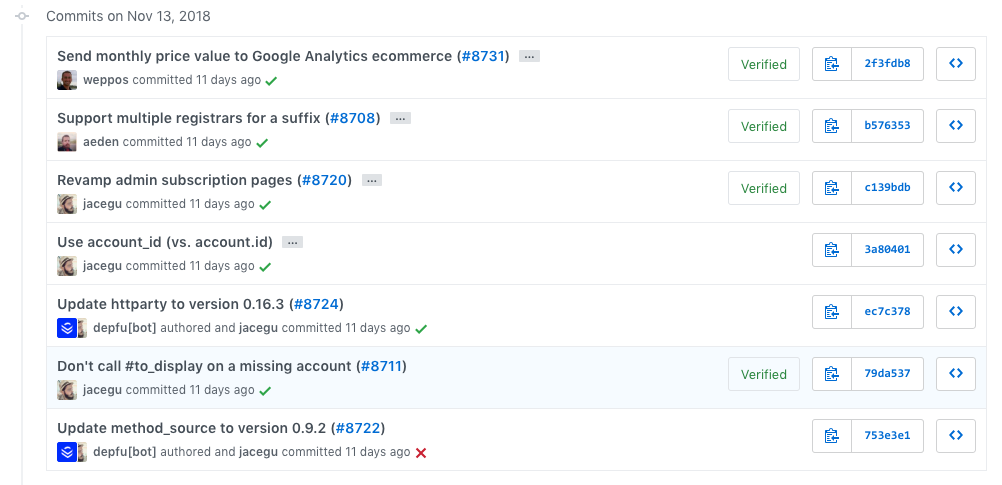
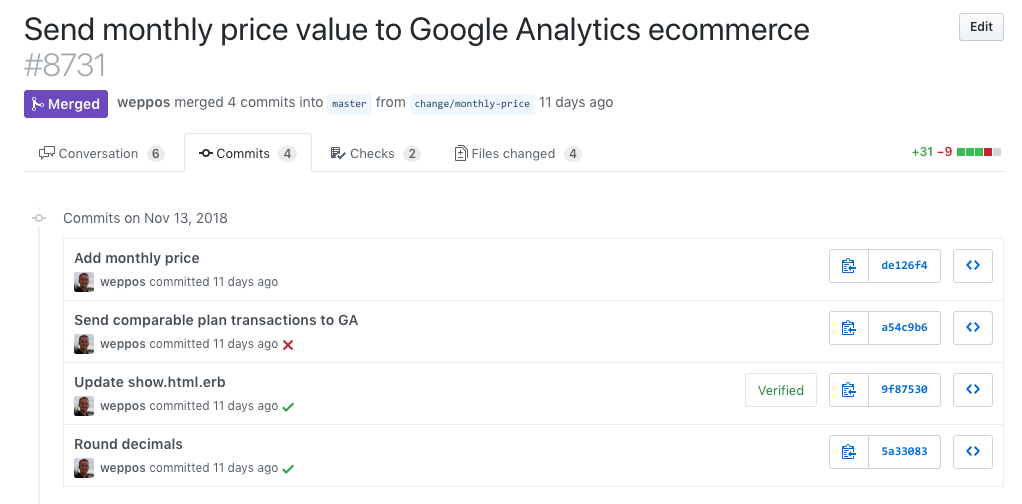
In case you are wondering if we are losing the individual changes, the answer is no. Each squash merge references back to a PR where the whole changes are tracked:
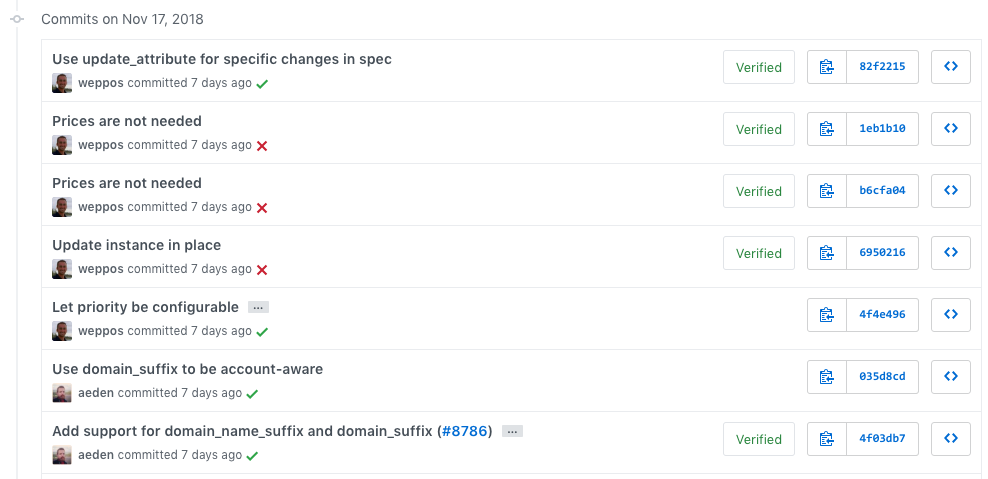
Occasionally, non-squash merge occurs. It happens. We're all human beings. But you can immediately see the difference when this happens:
Questions & Concerns
The use of squash merge is certainly not the only possible way to keep your version control history clean and readable. There are a number of best practices that each developer can adopt, individually or as a team. However, we found this feature to provide the best balance between simplicity, freedom, and results.
If you've been reading all the way to this point, you certainly have questions or comments. Here's the most common one I heard:
Aren't you discouraging individual commit quality?
No. Each committer is still encouraged to write good commits: combine together meaningful changes, along with explanatory commit messages. However, there is no peer pressure that a typo, a missing file, broken spec would end up cluttering the final primary branch.
You could use git rebase!
Yes, we can certainly use rebase to amend a commit message, or recombine commits. While this may work for local commits (and I frequently do it), rewriting the git history is discouraged once you've shared it (e.g. after you pushed it to the remote shared repository).
In fact, to prevent issues with teammates and continuous intgration tools, we explicitly forbid rebasing your commits after you've pushed them. We don't allow git push --force either. The only use case for --force or git rebase is in the rare case of severe issues that may compromise security or stability of the repository. But that's an exceptional use case.
You can use short-living branches to avoid repetitive merge of master
No, this doesn't work. It does if you have very few developers, each working on individual branches. But when multiple developers are working on multiple-feature branches together, that doesn't scale. We encourage backporting master often into your branch to limit the risk of conflicts, and stay on top of the latest changes. For example, we continuously update dependencies. We also merge and ship on average 10 times a day.
Conclusion
By using squash merge, we have been able to drastically improve the quality of our change history, turning our commit log into a very powerful tool to navigate:
-
We reduced (and in certain case even eliminated) the number of fixme, fix previous commit, fix specs commits to the repository. Mistakes happen, and the developer has full freedom to experiment, and even commit incomplete changesets in a branch with the full confidence that, once merged, only the final result will be shown.
-
The development of feature branches is now much easier. We can cherry-pick, backport, and even periodically merge back master into a development branch, without worrying about all the various recursive merges showing up in the logs and cluttering the history.
-
We increased the confidence of non-developers or non-technical team members to contribute. In particular, we can leverage the use of web UI to edit files in place. The final merge is still subject to our peer review process, and it is the responsibility of the leading member to merge the final changeset with an appropriate message. A great example is our current copy editing process, as shown in the following screenshot:
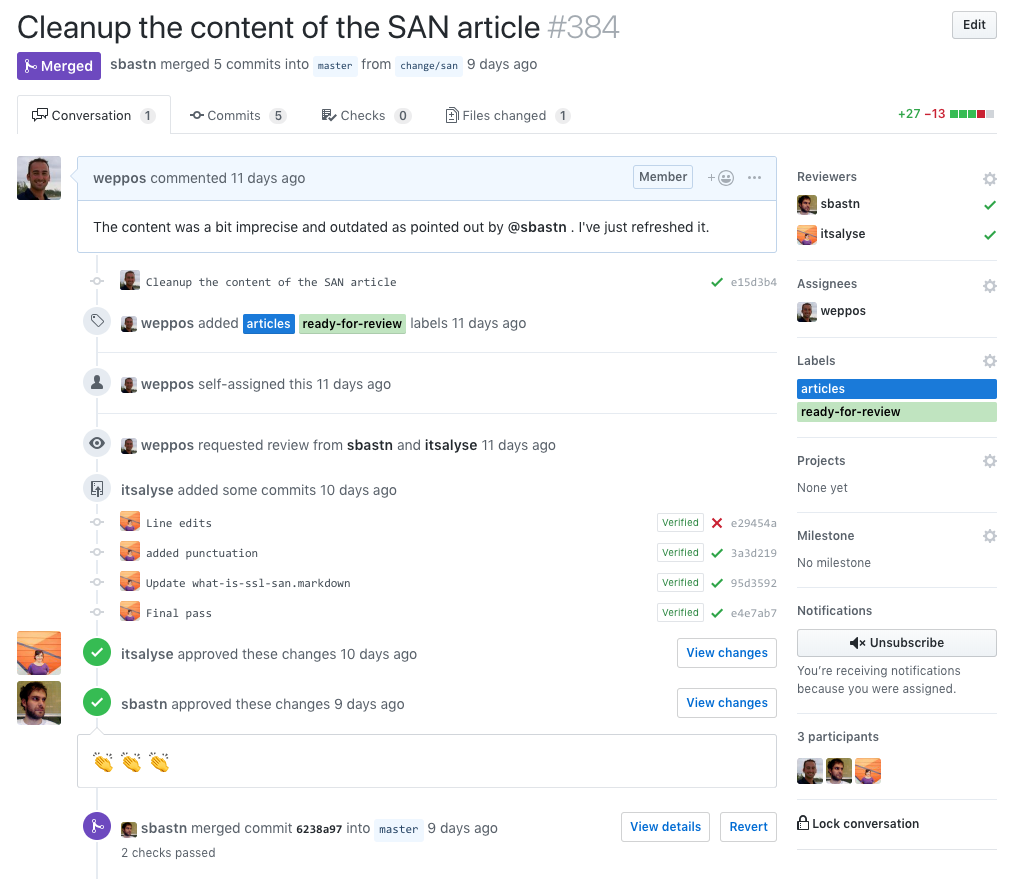
-
We simplified the rollback or revert process by packaging all the changes in a unique set at the very end of the git history.
-
We facilitated all the tasks that require navigating historical commits (e.g. via
git blame), such as debugging, reviews, and cleanup of technical debt. The main reason is that all the changes related to a particular feature are not included in the same changeset. If yougit blamea particular line of code and go to the commit diff, you'll get exactly all the associated changes including: methods that were created, spec files that were touched, views that were updated, etc. No more cases where you research why a method signature was changed, and the only changes you see in the commit are the method signature edit and (hopefully) the corresponding spec.
All these benefits result in a more maintainable code, less time spent chasing team members to get insights about why that line was changed, and more productivity with less stress.
Simone Carletti
Italian software developer, a PADI scuba instructor and a former professional sommelier. I make awesome code and troll Anthony for fun and profit.
We think domain management should be easy.
That's why we continue building DNSimple.


