Partial DNS outage
 Darrin Eden
on
Darrin Eden
on
On Friday, March 8th we had a partial DNS outage. Available and well performing DNS is a critical utility for the businesses our customers are running. We take this responsibility seriously. We continue to investigate the reason behind this outage and are working hard to prevent it from reoccurring. I would like to apologize to any of our customers who were affected by this event.
What we experienced
A few minutes past noon Pacific time (20:00 UTC) we began reading Tweets from several customers indicating there may be a problem. Throughout the event we received no alerts from various third-party monitoring tools we rely on. Nor did we receive any alerts from our internal monitoring systems. Since we expect our alerting system to light up if there's a DNS issue we considered it a surprising start to our investigation. We began by taking a high level view of the system from a network perspective to detect anomalies. The first tool we used is Boundary. In the following graph it seems Google started sending us a higher than normal number of questions.
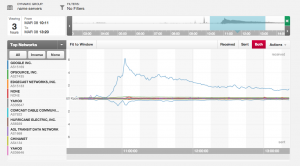
We took a deeper look at the traffic through packet captures. Google is almost exclusively asking for TXT records supporting DMARC from each of the domains we host several times over. At this point I'm speculating Google activated a new system that may have overloaded our resolvers. The overall traffic pattern seems to be subsiding, but I'm not certain as to why (or even if) this was the cause of the event.
What some customers experienced
Listening to our customers' reports we noticed a trend pointing to a geographically isolated event. Several customers mentioned resolution seemed normal on the East Coast while the West Coast was still having trouble. We also received a majority of reports that the problem affected New Relic clients more than other services. Many were triggered by New Relic alerting it was unable to resolve DNS for their application. For what it's worth the DNSimple web application uses New Relic and our own name resolution service. We weren't alerted by New Relic that there was a problem with name resolution.
Correlation does not imply causation
- Our clients on one service, in one geographic area contributed a majority of the outage reports.
- Our distributed, third-party monitoring tools we unable to detect an outage.
- We received an anomalous rise in traffic from Google at roughly the same time.
- Our name servers are globally distributed and largely isolated, but are unicast based at the moment.
From these observations I would expect either all customers to be affected and the alerting system to detect it or the traffic pattern to be remain normal while some other factor affected a region or service. That these events occurred practically simultaneously may be related, but at this point I don't understand how one would cause the other.
What we plan to do about it
I'm always disappointed when customers notice a problem before our monitoring system does. We will be working on another level of internal monitoring tools increasing our geographic diversity to detect issues. We will also investigate additional alerts that may be tied closer to pattern changes in network traffic. Finally, we are investing heavily in software and hardware that will dramatically increase the capacity and capability of our DNS service.
Summary
I am very sorry we weren't able to detect and respond to this issue before it affected DNSimple customers. While we continue to research the reasons behind this outage please know we are working hard to live up to the trust you've put in us to help operate an important part of the internet and your business.
Update 1
After corresponding with a New Relic engineer it seems Google DNS may indeed have had a spot of trouble today. Because Google's DNS is anycast based I believe it lends credence to a geographically concentrated outage.
Update 2
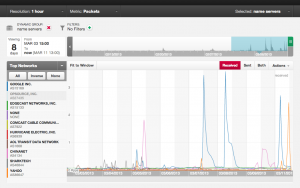
Our working theory is a spam botnet is involved in these events. Over the last several days we've seen a few query spikes (see image below) from Google and one from Yahoo seemingly related to SPF and DMARC (i.e. spam prevention) questions. An important fact I realized, following the initial event, is our query rate limiting system was part of the problem. Rate limiting is one defense we employ against a sudden and sustained traffic spike from a given IP address. We automatically throttle inbound questions in an attempt to protect our DNS software from being overwhelmed. If we assume those email networks are being flooded with messages such that an exceptionally high number of queries are generated it likely triggered our throttling defense. If the volume was significant enough many otherwise valid, "normal" queries from Google would timeout unanswered. As such this apparently reflects in Google's Public DNS and finally on services like New Relic that rely on that DNS service.
As of 1PM Pacific time on March 11th we've allowed the range of IP addresses we've seen from Google and Yahoo. We continue to monitor the situation and react as we learn more.
Darrin Eden
I like shiny things (it says so on my blog). I keep the machines humming at DNSimple.
We think domain management should be easy.
That's why we continue building DNSimple.



