Incident Report - DDoS Attack (September 19th, 2014)
 Anthony Eden
on
Anthony Eden
on
What happened?
On Saturday, September 19th, 2014 at approximately 11:17 UTC we experienced a preliminary DDoS attack aimed at a customer's domain name. The initial attack was primarily felt in our Tokyo data center. At 11:45 UTC we received initial reports from customers on Twitter reporting issues with their domain names. At 12:17 UTC the attack escalated significantly, impacting multiple data centers and causing a major DNS outage for our customers.
Here is the shape of the attack:
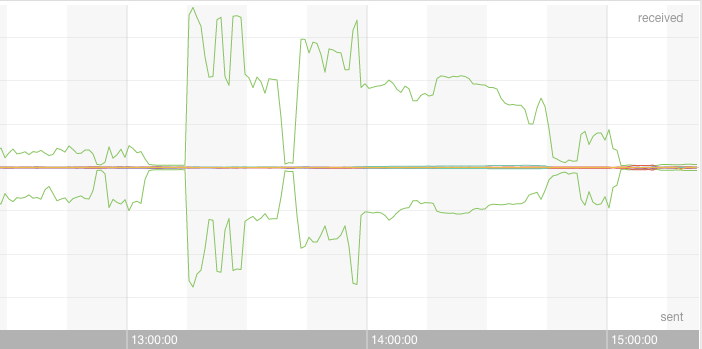
Why did it happen?
The outage was primarily due to the DDoS attack, however the effect of the attack continued even after the attack had subsided. The impact of volume of queries caused some of our name servers to stop responding to queries though they continued to broadcast themselves to the upstream routers. Other name servers were still responding but with significantly degraded performance, resulting in some responses being sent but others timing out.
Following the incident we spoke with the customer that was the target of the attack, however we were unable to determine the reason behind the attack.
How did we respond and recover?
When we began receiving reports on Twitter from our customers our first step was to review the network traffic patterns. The traffic patterns showed a spike in traffic, but those traffic levels appeared to be within the bounds of what our systems can handle. At this point our monitoring systems were not reporting the impact on the TKO data center as an outage, although later we determined that the Tokyo data center was in fact affected by the initial attack. When the second, larger attack occurred we begin receiving notifications from our monitoring system indicating issues in both our Tokyo and San Jose data centers.
At 12:24 UTC we posted the first notice to our status page and we contacted our network provider to inform them of the attack. Additionally we began looking for the target of the attack. After identifying the attack target we contacted the customer and requested that they change the delegation for the domain to another provider. Additionally we provided additional details to our network provider in hopes that they would be able to assist.
By 13:34 UTC the delegation was changed and the attack began to subside. At this point we were still seeing flapping on our servers and additionally noticed some of the physical nodes reporting memory warnings, which indicated that there were still issues on the servers after the attack. We began remotely connecting to servers by IP address, since the outage was still affecting resolution of our own host names we use to address our virtual containers, and we determined which servers were still responding to queries and which were not. Once we determined that at least one data center was fully operational we began removing the failed name servers from our Anycast network so we could repair them. By approximately 14:00 UTC we had removed the failed name servers and customer DNS resolution had returned to normal.
We began returning each failed name server to production one-by-one to avoid overloading our internal zone servers. By 15:30 UTC the majority of the name servers were fully operational. There were still some name servers that had residual issues and needed additional maintenance. By 16:10 UTC all name servers were returned to full operational capacity.
How might we prevent similar issues from occurring again?
Denial-of-service attacks will happen. While there is no way to prevent attacks, we, as your DNS service provider, can improve our mitigation strategies. We have either already started taking, or will take, the following steps:
- We are working with our managed systems provider to install defence devices in each of our data centers. These devices are designed to identify attack patterns and block them before they make it to our servers. We were already in the process of rolling out a device in our Chicago data center prior to this incident, and due to this incident we will accelerate the deployment of the devices to all data centers.
- We will discuss other DDoS defense options with various providers of these services and see what other options are available to protect our network from all forms of DDoS attacks.
- We will review our monitoring systems to determine how we can improve the timeliness of notifications, especially when traffic patterns diverge significantly from normal traffic.
- We will review our escalation policies with the engineering team to see if we can reduce the mean-time to response when incidents occur.
Conclusion
While attacks are inevitable, we still let our customers down by not being able to mitigate this attack faster. I am sorry that you were affected by this attack and I assure you we will continue to do everything in our power to improve our defensive capabilities for all of our customers. Thank you to everyone who provided positive support during this event, the entire DNSimple team appreciates it.
Update: 22 September 2014
Early this morning we discovered instances in two of our data centers (Virigina and Chicago) which appeared to be operating normally were, in fact, not behaving as expected. We believe that this was due to residual effects from the attack on Saturday.
The servers which were failing have now been restarted and are responding properly.
Due to this additional information, we will now add the following steps to those outlined above:
- We will update our incident response policies to include a slow restart of all name servers in all data centers once the system is properly stabalized after the incident.
- We will work on new tools to help monitor the health of the various name server subsystems to better identify latent issues such as this.
Anthony Eden
I break things so Simone continues to have plenty to do. I occasionally have useful ideas, like building a domain and DNS provider that doesn't suck.
We think domain management should be easy.
That's why we continue building DNSimple.



