Alerting at DNSimple
 Amelia Aronsohn
on
Amelia Aronsohn
on
Monitoring and alerting is one of the most important parts of operations, especially while operating distributed systems. Getting your alerting right can be difficult though since delivering the right alerts to the right places is critical and often finicky. You want to know not only when things break but also know when issues are just starting to arise so you can prevent downtime. This art of having notices from metrics show up where you can act on them in a timely manner and having important alerts go to people is can quickly become a double edged sword if handled with care and tuned over time. If you have non-actionable alerts being sent out frequently then you will quickly cause pager fatigue, which is almost worse than not getting notices at all.
A few months ago we started getting the followling several times a day.
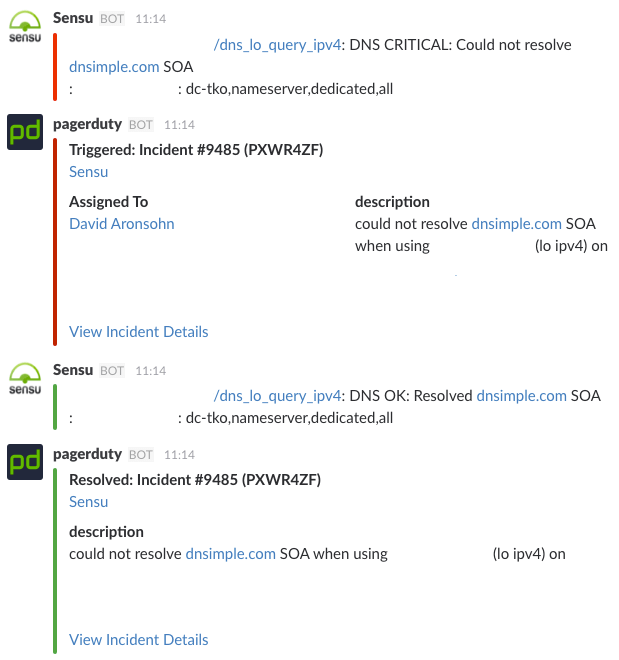
These alerts would resolve themselves even faster than we could react. Digging into this on the box and our app turned up nothing useful. This behavior became problematic more for us more than anything else as these alerts kept coming and were infuriatingly non-actionable. It was only after we set up better metric tracking and some dashboards did the picture really come into view.
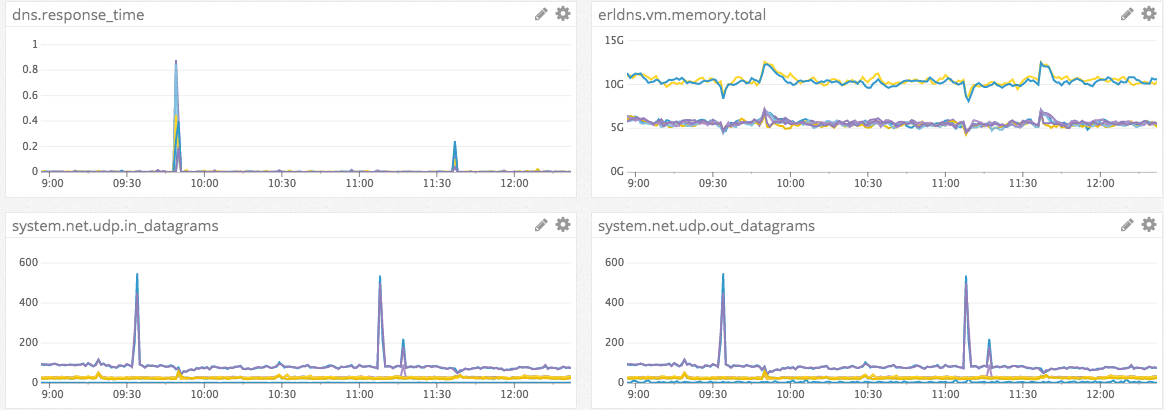
These incoming traffic floods would hit and quickly be followed by leaps in the resolve time. The servers never actually stopped resolving but once the response jumped over one second sensu consitered the check failed and then would recover immetdiately. Using this new information we were able to adjust our alerting and moved the monitor over to DataDog so we could not just watch for a spike in time, but a larger trend of rising resolve times.
Other than just having your alerts be actionable and based off of meaningful data it's important to make sure the right notices get where they are needed. Not every notice is an alert. We have many sources of these types of alerts in our stack. DataDog metrics, BugSnag, and Travis-CI are some of of our busiest streams of notices. We have most of these systems post to our main Slack channel so that everyone can see when either the application or our infrastructure is starting to have errors. As a global team we usually have someone around to triage these as needed and having the full team visibility is great for a small company like us.
For handling our more urgent alerting we use PagerDuty, a very popular pager rotation handler. Using our global presence once again to our advantage we have been able to set up our pager rotation so that we take on call shifts in twelve hour blocks, a week at a time. This way no one has to receive the dreaded four am pager notification.
The most important thing to remember when setting up your monitoring and notification is to keep it in flux. It should be the kind of system that evolves and grows with you and your environment. It's really easy to set up some quick notices and then get frustrated when they start sending up non-actionable flags.
Amelia Aronsohn
Kaizen junkie, list enthusiast, automation obsessor, unrepentant otaku, constantly impressed by how amazing technology is.
We think domain management should be easy.
That's why we continue building DNSimple.



