Migrating scheduled tasks from Clockwork to Sidekiq Enterprise
 Simone Carletti
on
Simone Carletti
on
At DNSimple we have a lot of scheduled tasks that run periodically during the day. We have standard tasks such as the one that processes open sales orders every few minutes or the one that collects payments. We have maintenance tasks like the one that purges expired domains and whois privacies from our system, and we have notification tasks like the process that sends you the domain expiring notification.
All these tasks have at least one feature in common: they must be scheduled periodically at specific points during the day, generally multiple times a day.
The most famous task scheduler is by far cron. There is no developer or system administrator that at some point during his/her career has not been exposed to this amazingly simple yet powerful piece of software. Most people remember it for the incredibly unique syntax used to define the time schedule.
┌───────────── minute (0 - 59)
│ ┌───────────── hour (0 - 23)
│ │ ┌───────────── day of month (1 - 31)
│ │ │ ┌───────────── month (1 - 12)
│ │ │ │ ┌───────────── day of week (0 - 6)
│ │ │ │ │
│ │ │ │ │
│ │ │ │ │
* * * * * command to execute
In this post I'm going to explain our decision to migrate our system for running scheduled jobs from Clockwork, open source software that we have been using for over 5 years, to Sidekiq Enterprise. I will provide the details of the analysis we performed prior to making the switch, the reasons we chose to make the change, and how we determined the success of the migration using the metrics we collect from our system.
Cron and Ruby (on Rails)
Despite the fact that cron is the the defacto standard for scheduled tasks it's not always the best choice.
If you have been following DNSimple you probably know that the main app behind dnsimple.com is a big Ruby on Rails application. In the Ruby on Rails ecosystem it's not very common to use cron to run scheduled job. Don't get me wrong, it's absolutely possible. In fact you have at least 2 different possibilities:
-
define a rake task that contains the code you want execute, and schedule the execution of the rake task via
cron:task :process_orders => [:environment] do puts "Done!" end* * * * * /rake process_orders -
create a Ruby script to be executed via
rails runner, and schedule the execution of the runner:#!/usr/bin/env ruby puts "Done!"* * * * * cd /path/to/rails/app; ./bin/rails runner ./lib/process_orders.rb
If there are at least 2 ways to successfully use cron with Rails why then this is not the preferred option? There are several reasons but the most important one for us was related to performance: each cron task runs as a completely new process and it must boot the entire Rails environment before being executed. That means it's not possible to boot the environment once and share it with different processes.
The issue may not be relevant for a new application but our application takes several seconds to boot in production and this makes the execution of a lot of tasks, especially the ones with high frequency, quite inefficient.
Let's look at a simple example. If your application takes 10 seconds to load and you have 5 tasks that has to run every minute, it means that you spend 50 seconds per minute only to boot Rails instances. Things get worse if your application takes longer and you have tasks that needs to run every few seconds: for example if you have a task that runs every 10 seconds and your Rails app takes 30 seconds to load, then you will eventually run into a resource starvation problem.
There are also additional disadvantages related to memory management, error handling, and process handling. As we'll see in a second this solution is also quite inefficient if you have a large number of small periodic tasks that spawn async tasks, and you need to scale them.
For these reasons and others I did not mention here, if you need to execute periodic tasks with Rails you generally want to adopt a different scheduling software that is at least capable of reusing the Rails environment once it is loaded.
Hello Clockwork
clockwork is a cron replacement written in Ruby. Quoting the README: It runs as a lightweight, long-running Ruby process which sits alongside your web processes (Mongrel/Thin) and your worker processes (DJ/Resque/Minion/Stalker) to schedule recurring work at particular times or dates.
clockwork has a long history. It was originally developed by Adam Wiggins at Heroku and it's one of the most common scheduling solutions for Ruby software in general, and in particular, Ruby on Rails applications.
At DNSimple we have been using clockwork for years. For the sake of my curiosity I decided to dig into our git repository to find when it was first introduced and this is what I found:
commit e027fda7e50b9b8741d46e559b903b938c4ab7da
Author: Anthony Eden <anthonyeden@gmail.com>
Date: Sat Oct 22 18:54:50 2011 -0400
Use clockwork to send renewal notifications.
The gem was added as a dependency on October 2011 to handle the delivery of the expiring notifications.
diff --git a/app/workers/send_renewal_notifications.rb b/app/workers/send_renewal_notifications.rb
+class SendRenewalNotifications
+ @queue = :renewal_notifications
+
+ def self.perform
+ DomainTools.send_renewal_notifications
+ end
+end
diff --git a/app/config/clock.rb b/app/config/clock.rb
+require_relative '../config/boot'
+require_relative '../config/environment'
+
+every(1.day, 'renewal-notifications') { Resque.enqueue(SendRenewalNotifications) }
When we decided to replace clockwork we were using it to handle more than 30 different tasks, each of them resulting in hundreds of thousands jobs processed per day.
Clockwork or not?
In the previous section I already alluded that we eventually ended up replacing clockwork. You may be wondering why.
In reality, for the most common scenarios, clockwork works absolutely fine. After all we used it for over 5 years. If you need to run a single idempotent script periodically or at specific times, with limited interaction with the database or other components, then clockwork will likely be your best friend forever.
But when your application grows and/or your tasks become more complex, then you start hitting some limitations of clockwork.
Here are the issues that eventually become a pain for us:
- task re-scheduling on restart:
clockworkdoesn't have a persistent memory; on every restart it loads the list of jobs to execute and triggers them based on the configuration.
Our deploy recipe was designed to restart clockwork after each deploy, to reload the changes to the scheduled configuration and the Rails environment. However, the side effect of the process restart was that clockwork was re-triggering a large portion of the tasks, ignoring that some of them were already executed perhaps a few minutes before.
This issue was even more evident on tasks that were scheduled with a long interval, such as once a day. If we deployed our application 25 times in a day clockwork would have been restarted 25 times and each time it re-executed the daily task.
Of course, this was less than ideal and we had to start to include logic in our application to deal with task re-scheduling. Almost every task that was time-sensitive had a guard condition that prevented the task to run if it was already executed in the desired time-frame.
module Clockwork
every(10.minutes, 'sales_orders.process_orders') {
SalesOrderProcessOverlord.perform_async
}
every(1.day, 'domains.update_expired_domains') {
throttle(DomainUpdateExpiredOverlord, 12.hours) { DomainUpdateExpiredOverlord.perform_async }
}
every(1.day, 'domains.remove_expired_domains') {
throttle(DomainRemoveExpiredOverlord, 12.hours) { DomainRemoveExpiredOverlord.perform_async }
}
def self.throttle(worker, frequency, &block)
Dnsimple::Officer.throttle("worker:#{worker}", frequency, &block)
end
end
- incompatibility with redundant architecture: in the last year we invested a lot of time and resources to ensure the high availability of our systems. Nowadays all our web applications run on a minimum of 2 machines.
To avoid a single point of failure we made the decision to replicate the same environments on all machines, including scheduled tasks, instead of having the tasks being enqueued on a single machine (that could be offline at any time due to maintenance, deploys, issues, etc).
However, clockwork doesn't include any jobs synchronization mechanism - the nodes don't talk each other and as a result we started to experience job duplication caused by the duplicate scheduling of the same task from different machines.
In several cases the throttle mechanism introduced to fix the previous issue worked well to limit the duplicate jobs. However, without entering too much into the details, there were some race conditions caused by jobs run almost in parallel (within milliseconds of difference) that were able to bypass the throttle mechanism and required a more sophisticated synchronization mechanism. We started to adopt Redis (that has atomic sequential operations, hence we could guarantee an effective distributed lock), which resulted in more code complexity.
module Clock
class InvoiceCollectionJob
include Clock::Job
def run
InvoiceFinder.to_be_collected.ids.each do |invoice_id|
run_once(invoice_id) { InvoiceCollectWorker.perform_async(invoice_id) }
end
end
end
end
Additionally, after a few years we started to experience Redis failures and memory errors, caused by (apparently unpredictable) spikes in the number of Redis connections, which in turn caused jobs to fail. It took us almost 3 months of debugging to determine the causes of the issue and update all our code to properly use a Redis connection pool to fix the memory leak.
- duplicate jobs: in some circumstances, the execution of
clockworkresulted in duplicate jobs. This is not an issue withclockworkitself, rather a result of some of our design decisions. As an example, during deployment, our queue processing is stopped and jobs scheduled every minute may queue up until the deploy is completed.
As a result, some jobs may be enqueued multiple times. It's not necessarily the responsibility of the scheduler to determine whether an existing identical job is already queued for execution, however this particular scenario required us to introduce extra code to ensure some tasks would not be enqueued again if an existing identical job was waiting to be processed.
These major issues pushed us to start looking into possible replacements for clockwork.
Welcome Sidekiq Enterprise
Sidekiq Enterprise is a paid version of Sidekiq, one of the most popular background processing library written in Ruby. The Enterprise version provides extra features on top of those provided by Sidekiq Pro and Sidekiq Standard, including one called Periodic Jobs that supports defining scheduled tasks.
Since we already used Sidekiq and Sidekiq Pro, we decided to give Sidekiq Enterprise a try. In order to commit to the full upgrade, the minimum requirement was to solve at least the issue (1) and (2). However, Sidekiq Enterprise also provides an Unique Job feature, that seemed to be appropriate to solve also issue (3).
We tried Sidekiq Enterprise in parallel with Clockwork for 1 week: we migrated an initial batch of tasks from Clockwork to Sidekiq and we check that the tasks were properly executed. The migration was very easy, as the task-based approach required by Sidekiq was exactly the solution that we already used for Clockwork. I'll talk about this pattern in more details in the next section.
diff --git a/config/initializers/sidekiq.rb b/config/initializers/sidekiq.rb
+Sidekiq.configure_server do |config|
config.periodic do |mgr|
+
+ # Tasks
+
+ mgr.register("*/10 * * * *", SalesOrderProcessOverlord)
+ mgr.register("0 * * * *", SalesOrderMonitorWorker)
+
+ mgr.register("0 */4 * * *", InvoiceRetryOverlord)
+
+
+ # Metrics
+
+ mgr.register("* * * * *", GenericMetricsSubmitWorker)
+ mgr.register("* * * * *", FixmeMetricsSubmitWorker)
+
+end
diff --git a/lib/clock.rb b/lib/clock.rb
- every(10.minutes, 'sales_orders.process_orders') {
- SalesOrderProcessOverlord.perform_async
- }
- every(30.minutes, 'sales_orders.monitor_sales_orders') {
- SalesOrderMonitorWorker.perform_async
- }
- every(4.hours, 'invoices.retry_failed') {
- InvoiceRetryOverlord.perform_async
- }
-
-
- # Metrics
-
- every(1.minute, 'metrics.generic') {
- MetricsSubmitWorker.perform_async(Dnsimple::GenericMetrics)
- }
- every(1.minute, 'metrics.fixme') {
- MetricsSubmitWorker.perform_async(Dnsimple::FixmeMetrics)
- }
Both the overlords and the metrics are tasks that are enqueued quite frequently and that were not guarded by any throttle mechanism: that means, these tasks were the most affected by the redundant architecture issue described at point (2).
By moving these tasks first, we achieved two goals:
- move frequently run tasks, that can be quickly re-scheduled in case of issue (hence a failure in the transition would not have a big impact on the system or affect our customers)
- determine the impact of Sidekiq Enterprise on the scheduled jobs, and whether it represents a solution to the issue (2)
At DNSimple we collect several metrics about our system, including the execution of background jobs. The impact was determined analyzing the number of jobs processed for the migrated tasks.
We deployed the first change on February 28th. The impact is quite evident, the total amount of jobs processed every 2 hours immediately dropped from 102k to 70k.
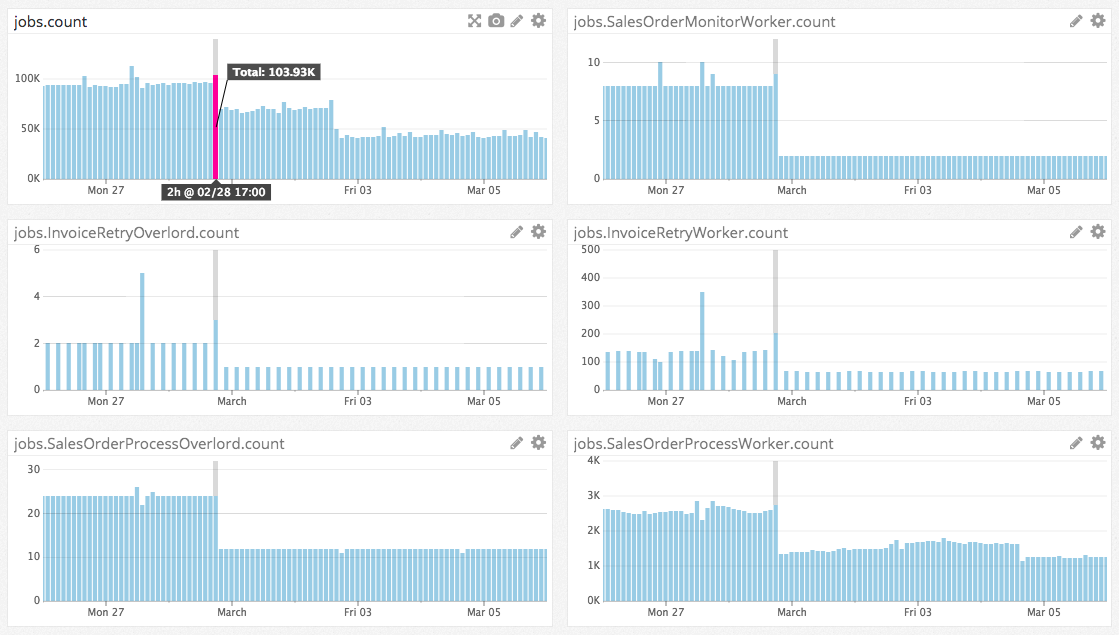
The number of tasks queued for each overlord dropped, as expected, by at least 50% (we were running 2 servers in production at that time), confirming that Sidekiq Enterprise is effectively able to properly synchronize the jobs across several machines and run the scheduled task on only one of the running nodes.
To determine the impact of Sidekiq Enterprise on the issue (1) we took a completely different approach. I mentioned that the issue (1) was more evident on tasks with a low frequency, therefore we migrated some tasks that were queued once a day.
We deployed the change on March 3rd. The number of jobs did not change, as expected, however you can easily notice how the execution time started to follow very consistent patterns.
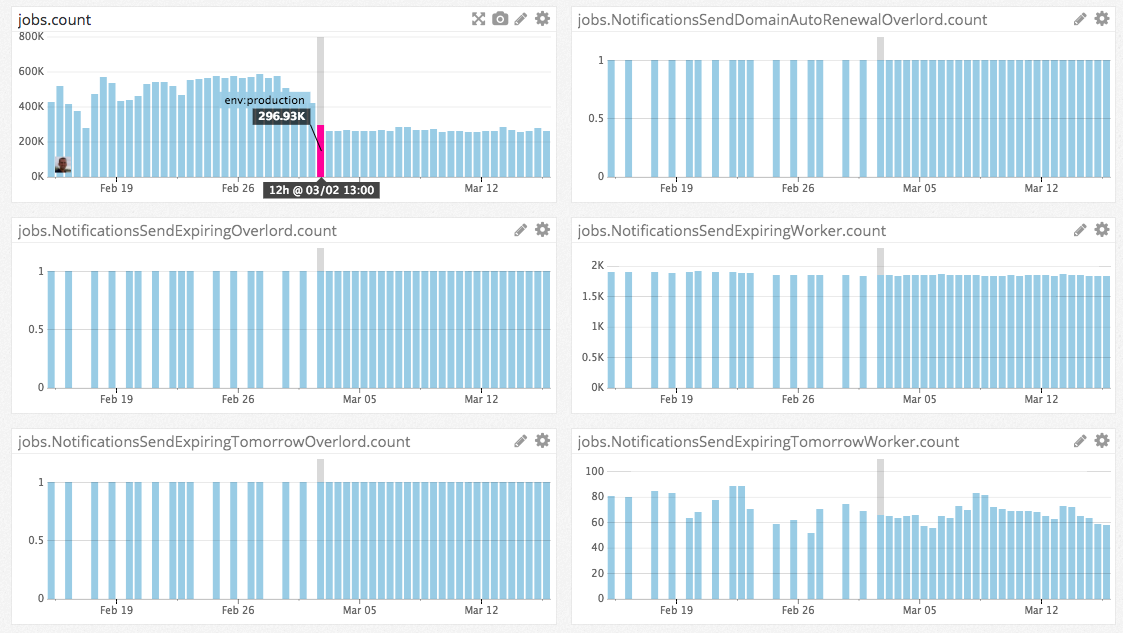
Before, the tasks were enqueued either when the scheduled time occurred, or the service was restarted. Using Sidekiq Enterprise, we were able to achieve a consistent execution, exactly at the time the job was planned. That also allowed us to increase the frequency of these tasks from once a day, to twice a day (distributing the load on our system).
Using our metrics, we were also able to determine the successful deployment of the unique job feature, that allowed us to further reduce the amount of queued jobs, eliminating the issue where multiple instances of the same overlords were enqueued multiple times when the queue is stopped, for example during deploys.
We successfully completed the replacement of Clockwork with Sidekiq Ent on March 21st.
commit b5e6176a07234a46b69a3d47ea8379f005619364
Author: Simone Carletti <weppos@weppos.net>
Date: Tue Mar 21 17:54:28 2017 +0800
Remove clockwork (#4849)
In total, the migration took about 3 months, including the testing and monitoring phase. This task was also one of the first pilot projects that we defined using the project template, as explained by Anthony in his post.
In total, the feature took approximately a couple of days of work. The time tracking is not perfectly accurate as that was the time we just closed our time tracking experiment and some team members (including myself) moved to their own time tracking solution. However, I think it's definitely an interesting measurement that highlights the unexpected simplicity of migrating to Sidekiq Enterprise, especially if you are already using Sidekiq.
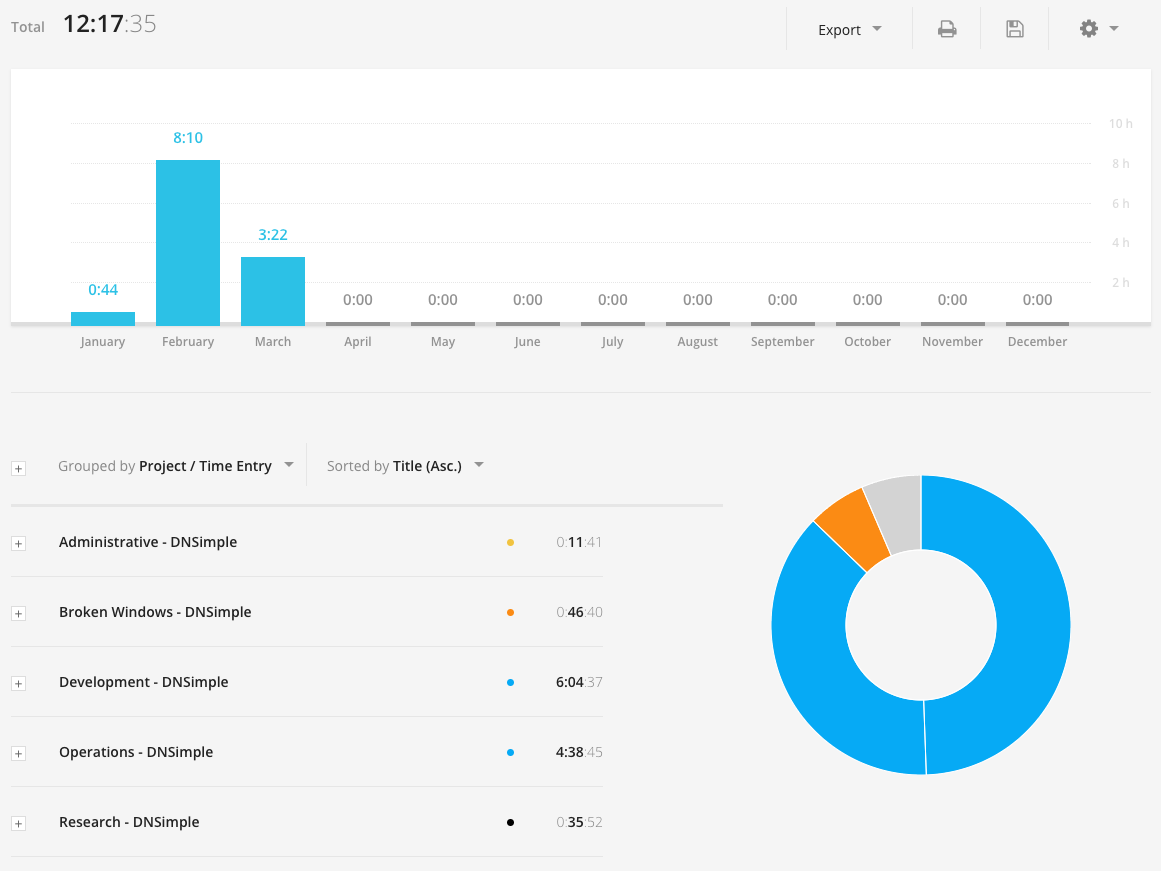
It's also important to mention again that, in our case, we already had most of the architecture in place that allowed us to migrate from Clockwork to Sidekiq Enterprise with close-to-zero new development effort.
The architecture we adopted for our scheduled task scaled very well for us over the last few years, but it would be too much to add a full explanation here. I promise we'll provide more information in a future post, in particular the difference between Workers and Overlords.
Results
The adoption of Sidekiq Enterprise allowed us to fix several recurring issues we were experiencing with previous solutions, and we were able to drop the number of jobs executed per day from ~1.1M to 600k.
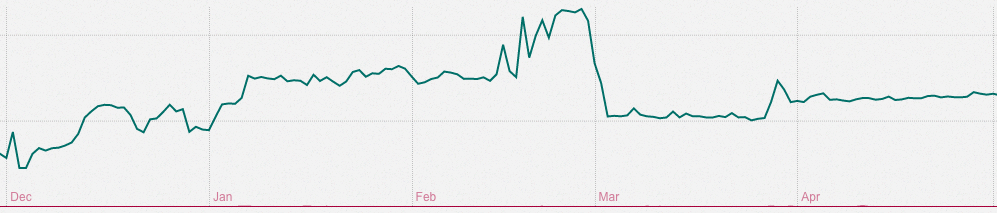
We are now also able to scale the number of our production nodes, with no impact at all on the scheduler.
Sidekiq Enterprise is not a free product, nor is it the only possible replacement for Clockwork. In our case, since we were already using Sidekiq and Sidekiq Pro, the upgrade to Sidekiq Enterprise was quite painless and gave us the opportunity to solve the existing issues with a reasonable time and money investment.
Sidekiq Enterprise may or may not work for you. Regardless the choice you'll make, make sure you have clear goals in mind and you have the necessary tools and metrics to measure whether the new product effectively satisfies your requirements.
Simone Carletti
Italian software developer, a PADI scuba instructor and a former professional sommelier. I make awesome code and troll Anthony for fun and profit.
We think domain management should be easy.
That's why we continue building DNSimple.


