Automated green/blue deploys with Hubot
 Ole Michaelis
on
Ole Michaelis
on
Here at DNSimple we make use of GitHubs Hubot a lot. We rely on it especially for deploying our main ruby application.
We do a blue/green deployment process, so that we can deploy our application without any downtime for you, our customers and partners.
In the past what Hubot basically did was executing a (ruby) script on the machines via a go server. We call it go-remote-control.
Deploying our application was a three step process:
- Prepare blue and green sides (stopping sidekiq and set downtime for monitoring).
- Deploy first side, either green or blue (remove server from BGP announcement, stop webserver, deploy, and start everything again).
- Deploy the remaining side.
After each step the bot posted the output of that script back to the chat and it was up to the human that triggered the deploy to check the output for errors and continue deploying if everything went just fine.
That process was working fine for experienced engineers. But for newcomers, like myself, it was frightening, especially when something went actually wrong. Worst was the fear of not recognizing that something went south.
I decided I wanted to improve the deployment. Because as I was learning (through asking) what a successful output looks like. I thought it makes sense to codify it right away. That way the next hire will have a easier time on their first deploy.
As a first step I implemented a state-machine within the bot that keeps track of the current state of the deployment. So that you would not deploy the blue side twice or forget to deploy green.
With the state machine in place it was a easy reach to implement what we called the AUTOMATED DEPLOY TRAINING it was basically just a message what the bot thinks is the correct next step to do. This servred two purposes:
- People could copy the command to execute next.
- Building up trust to the automated deploy mechanics.
I think especially the second step helped a lot for the acceptance of the new way of deploying within the team.
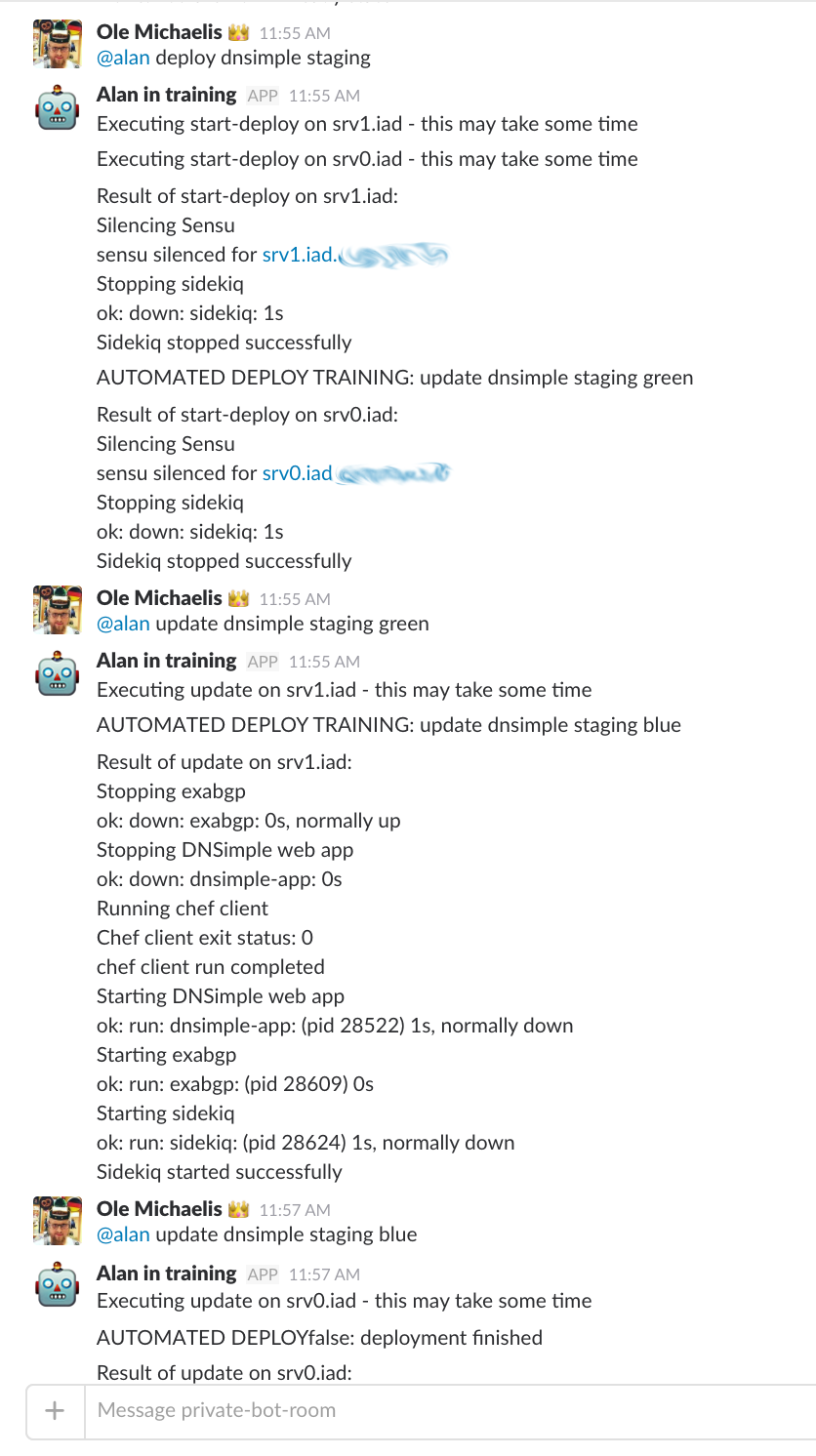
With this in place I could start to improve the training process while not touching the actual deploy, like checking the script output via regex for success messages. And whenever the bot detected a failure it would just stop right away and let the human fix it.
While operating that way we learned that in a failed deployment situation you need everything close by and all tools ready at hand. Because there usually is some stress involved when your application is down. We improved all error messages with the next possible commands and also implemented a deploy help command. That displays the current state of the deploy alongside with some explanations. Basically so that there is no need for external documentation. Even tough we still have it.
After a few weeks with this training mode on, and me also gaining trust in the automated deploy, we implemented a optional flag to automate the whole deployment. So that the bot instead of just displaying the command it would rather execute it.
Everyone could choose to deploy in a automated fashion, first some of us started with staging deploys and afterwards moving towards production deploys. We fixed the occurring errors that way and made the automated deploys the default after about a month.
As a last step we are now even hiding the output of a successful run and only show it when something goes wrong.
That is what our deploy looks like now:
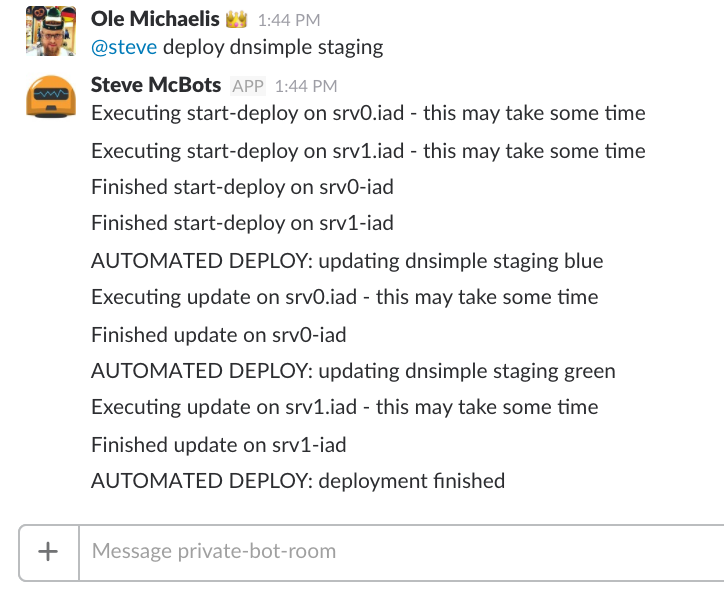
We took the effort to automate the deploys to remove friction from the deploy process, onboard new co workers quicker and ship new features faster to you!
Ole Michaelis
Conference junkie, user groupie and boardgame geek also knows how to juggle. Oh, and software.
We think domain management should be easy.
That's why we continue building DNSimple.



